![Fetch as Googleの使い方 [Search Console]](https://netotas.com/wp/wp-content/uploads/2015/11/search-console-fetch-as-google-1024x512.jpg)
意外と知られていないSearch ConsoleのFetch as Googleの使い方をまとめました。
- 基本的な使い方
- いつ使うべきか?
- よくある疑問点
- 使うときの注意点
Fetch as Googleは、記事公開後すぐに検索結果に表示させるなど、サイトのアクセスを増やすためには欠かせないサービスです。ぜひ、ご覧ください。
目次
Search ConsoleのFetch as Googleの使い方
Fetch as Googleを使うためには、Search Consoleにサイトが登録されていなければなりません。登録していることを前提に解説します。
Fetch as Googleとはなにか?
Fetch as Googleは、Search Consoleで提供されているサービスの一つでGoogleのクローラーを呼ぶための依頼をするサービスです。
このクローラーによって集められたウェブページの情報がGoogleにインデックスされると、Google検索の検索結果に表示されるようになります。
つまり、新たに公開したウェブページ(ブログ記事)を、すぐに検索結果に表示させたい場合などに使用します。超端的にいうと、アクセスを増やすことができます。
クローラーを呼びたいURLを指定する
Search Consoleにアクセスします。
Fetch as Googleを使うには、Search Consoleのダッシュボードで、①クロール>②Fetch as Googleをクリックします。
その後、③GoogleにクロールしてほしいページURLを入力し、④[取得]をクリックします。
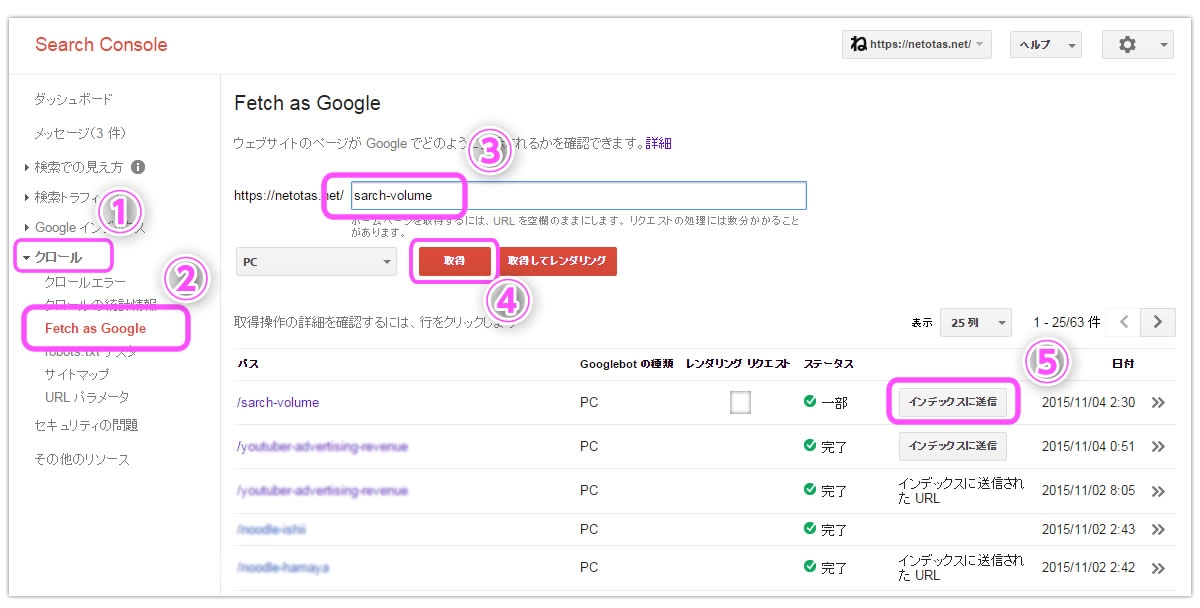
(※画像クリックで拡大できます)
インデックスに送信する
[取得]しただけでは、Googleのクローラーはやってきません。⑤の[インデックスに送信]をクリックして依頼完了となります。
インデックス送信は、下記、2つの方法があるので用途にあう方で[送信]しましょう。
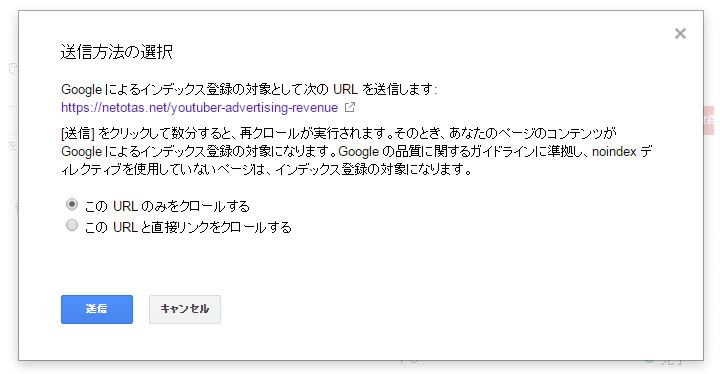
1.このURLのみをクロールする
一般的にはこれを使用します。送信したURLのみが再クロールされます。月間500件までの制限がありますが、大手メディアでない限り制限数を気にする必要はありません。
例:https://netotas.net/youtuber-advertising-revenue
2.この URL と直接リンクをクロールする
大幅に改変した際に使用します。送信したURLと直接リンクされたページが再クロールされます。個別ページではなく、TOPページや一覧ページのURLを送信するのが一般的です。通常月間10件までの制限がある点に注意してください。
例:https://netotas.net/category/web
[送信]をクリックすると作業は完了です。
あとはインデックス登録されるのを待ちましょう!
Fetch as Googleはいつ使うべき?
新規ページを追加した時
Googleの検索結果に早く表示してもらうためです。
検索結果に表示してもらうためには、Google検索エンジンのインデックスに登録してもらう必要があります。
Googleのクローラーは更新されていないかと常にウェブサイトを巡回していますが、いつあなたのウェブサイトにやってくるか分かりません。
つまり、サイトに新たにページを追加しても、クローラーがやって来てインデックスに登録されなければ検索結果には表示されないんです。
Fetch as Googleを使って、クロールの依頼をしましょう。
ページを改変した時
ページの修正を早く反映してもらうためです。
Googleの検索結果はインデックス化された内容で判断、検索結果に表示されます。
間違いを訂正した場合、SEO対策目的で修正した場合…どんな場合でも、何かしら目的があり修正したわけですから、やはりウェブページを修正した場合もFetch as Googleを使って再クロールを依頼した方がよいです。
Fetch as Googleの疑問点
送信してから登録されるまでの時間は?
[送信] をクリックして数分すると、再クロールが実行されます。そのとき、あなたのページのコンテンツが Google によるインデックス登録の対象になります。引用元:Search Console ヘルプ
再クロールはすぐに実行されます。ただし、インデックス登録されるまでの時間は評価の高いサイトが優先される傾向にあります。
Googleが重要だと認識されているサイトやページは即反映されますが、更新頻度の低いサイトやはり時間がかかります。
取得してレンダリングって何?
URLを取得する際に、[取得]と[取得してレンダリング]の2つがあります。結論からいうと、基本的には[取得]で大丈夫です。
取得してレンダリングを使用すると、Googlebotの認識とブラウザの表示を確認できます。
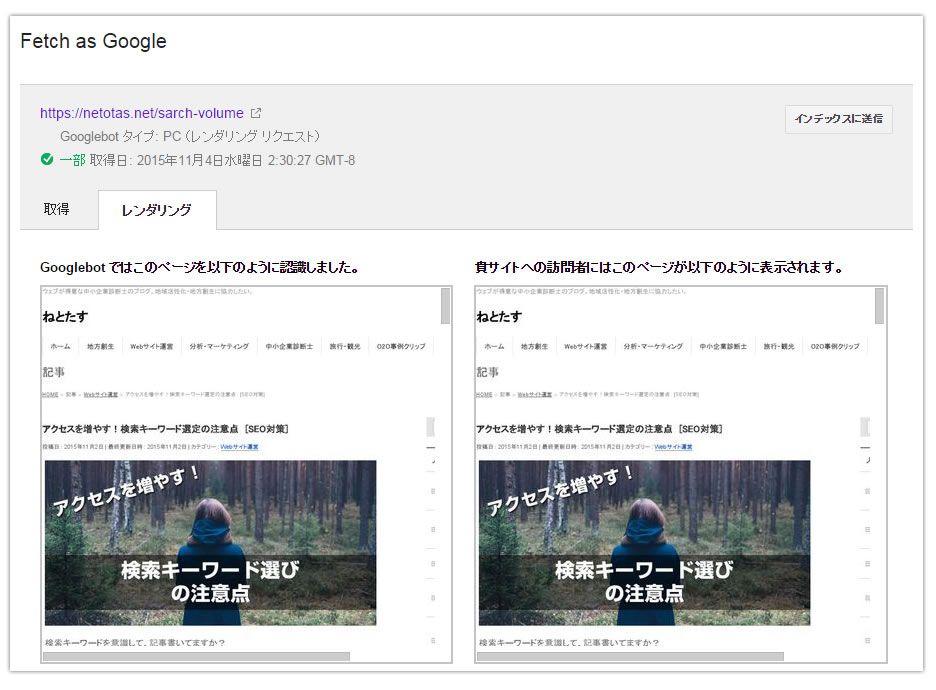
差異がある場合、「Googlebotはこのページの一部のリソースを取得できませんでした。」と取得できなかったリソースを表示してくれます。
レンダリングに時間がかかるため、通常では使用しませんし、[取得]と[取得してレンダリング]をどちらを使っても、インデックスされるまでの時間がかわるわけでもありません。
Fetch as Googleを使うときの注意点
「まぁそのうちクロールされるだろう…」は危険
なぜだか分かりますか?
たとえば、あなたが新たな記事を書いて公開したとしましょう。
新たな記事がGoogleにインデックス登録される前に、他人があならの記事をコピペしてページを作成て、あなたよりも先にGoogleにインデックス登録された場合、あなたの記事が重複コンテンツとしてみなされる場合があります。
盗用されただけは済みません。
重複コンテンツの場合、ペナルティを受けます。具体的にはGoogleの検索結果に表示されなくなります。もちろんオリジナルはあなたの記事はであり、著作権を有しているのでペナルティを解除することは可能です。
ただし、この誤解を解いている間に情報の旬が過ぎる可能性があります。そんなリスクを背負う必要はないので、とりあえず記事を更新したらFetch as Googleを使ってクロールの依頼を出しておくとよいと思います。
ページをキャッシュしている場合は、一旦キャッシュを削除する
インデックスに送信する前に、「ダウンロードされた HTTP レスポンス:」を確認するとよいでしょう。
たとえば、WordPressでWP Super CacheやW3 Total Cache、Hyper Cacheなどのキャッシュ系のプラグインを使用している場合が該当します。

更新したつもりでも、キャッシュされたページ(更新前のページ)を渡している場合があります。